Python
Python lets you work quickly and integrate systems more effectively.
A crash course on Machine Learning and Distributed Computing Frameworks in Data-centers
Data-Centric Computing - Barcelona Supercomputing CenterIntel Academic Education Mindshare Initiative for AI
Artificial Intelligence, Data Science and Machine Learning are nowadays present in many research fields and engineering works. Applying such techniques often involve big volumes of data, heavy processes requiring lots of hours of computing, large amounts of repetitive executions or exhaustive experiments to be run. In those situations, running experiments or applications in our laptop or even in our workstation is not enough, and we need bigger machines found in data-centers.
As not everyone is familiar with the capabilities of High Performance Computing (HPC) environments and the capabilities they offer, like distribution of data processes, in this course we will go through basic concepts like performance, parallelism or virtualization. On the other hand, for those who need to run but are not familiar with machine learning and data analytics processes, we will overview those concepts, including supervised and unsupervised learning, also neural networks, understanding that the different machine learning experiments can leverage parallelism and HPC. Aside of some theory introducing the important concepts, this course is fundamentally based on practice and experimentation, introducing some cases of use and exercises on Apache Spark, a platform for distributing data processes, and Intel BigDL, a Spark library optimized for neural network and Deep Learning.
The contents of the course are materialized as a set of Video tutorials, including the corresponding presented slides, and exercises that the student can follow and practice at home, in order to understand and experiment through examples of the contents here presented. Additionally, we are providing scripts and guides to set-up the different technologies here shown, for the students to deploy those environments at home and at work.
Video Tutorials
+5 hours
Chapters
3 Topics
Assignments
8 Exercises
Examples
11 Notebooks & 3 Demo Scripts
This is the version v.1 of the course. We will continue improving and adding material to this course with received feedback, also methods and technology updates.
Students, Researchers and Professionals
This tutorial is an introductory course for those undergraduate CS students that want to practice with some AI and data-center examples, to those professionals from different disciplines requiring AI algorithms and data-center resources for their daily jobs, and researchers from non-CS fields that can leverage HPC systems and AI frameworks to enhance their research and experiments with data. This is not an advanced course, so if you already know about machine learning or computer architecture and systems, probably you will only be interested in some parts of this tutorial, but anyway we invite you to check it out in case you can find something new to learn. We have prepared this course thinking in those researchers working around us at the Barcelona Supercomputing Center and in partner research groups, that being from fields like Mathematics, Biology, Genomics or Earth sciences, have the need to use big computers to process large amounts of experiments, but never had the occasion to use frameworks that definitely can improve their daily work at the lab or office.
Sponsors
This course has been financed in part by the Intel's Academic Educational Mindshare Initiative for AI, allowing us to present the following tutorials and hands-on examples. All the technologies here presented have some kind of Free or OpenSource license, avoiding restrictive software. Also although we will show preference to technologies provided by Intel, the students will find plenty of alternative techologies from other companies and foundations, in case they please or have some other preference or constrain. So don't worry if you have to use other libraries different from ours, as all the concepts here presented are "universal" in computer sciences and we use such technologies as a way to materialize them.
Who are we
We are the Data Centric Computing research group, at the Barcelona Supercomputing Center. This effort has been carried on by PhD. Josep L. Berral and Eng. Francisco Javier Jurado. Our main objective is to make easier to professionals of different disciplines and sciences to understand these new technologies of AI, computers and data sciences. We want to thank also D.Carrera (BSC, UPC), A.Gutierrez-Torre (BSC), D.Buchaca (BSC), F.Portella (BSC, Petrobras) and N.Poggi (Databricks) for their support and help on this project. Also special thanks to the people from Communications at BSC.
Technologies used in this Course
Python lets you work quickly and integrate systems more effectively.

Fast and general engine for large-scale data processing.
BigDL is a distributed deep learning library for Apache Spark.
VirtualBox is an x86 and AMD64/Intel64 virtualization hypervisor.
Magistral Classes and Hands-On Demos
Here you can find the three main chapters of this tutorial: 1) Data-Centers, 2) Machine Learning and 3) Hands-On Spark. Each chapter will provide a set of video-tutorials and their corresponding slides, plus some exercises that you can try at home, laboratory or office. For the two first chapters, video-tutorials will focus on theory and fundamental concepts of High Performance Computing and Machine Learning, while the third chapter will provide some concepts on Apache Spark and Intel BigDL, then focus on practical examples that should be followed by the students in their our machines. For the exercises, you will find documents with some guided assignments providing additional practical examples.
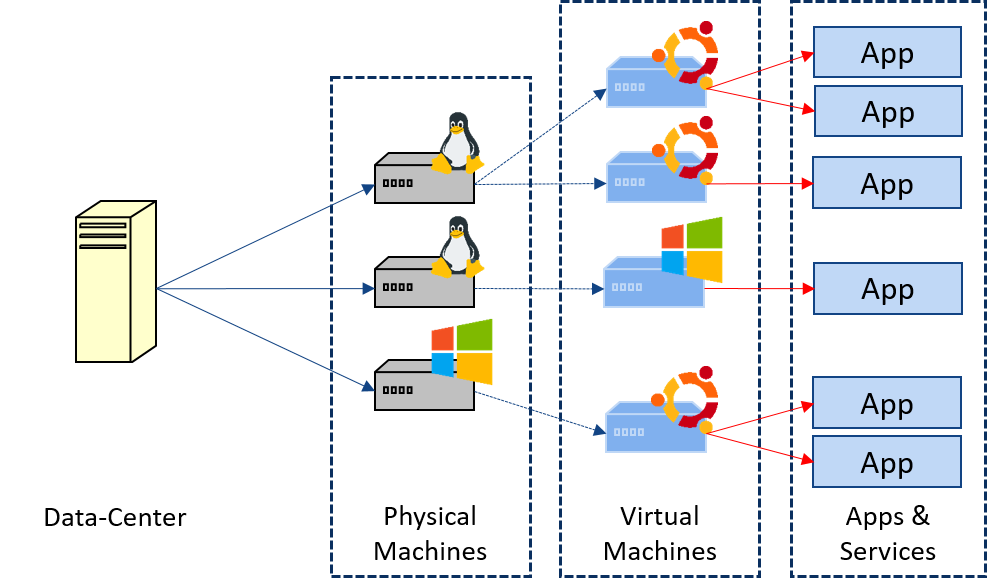
Chapter 1
High Performance Computing, the Cloud and Virtualization.
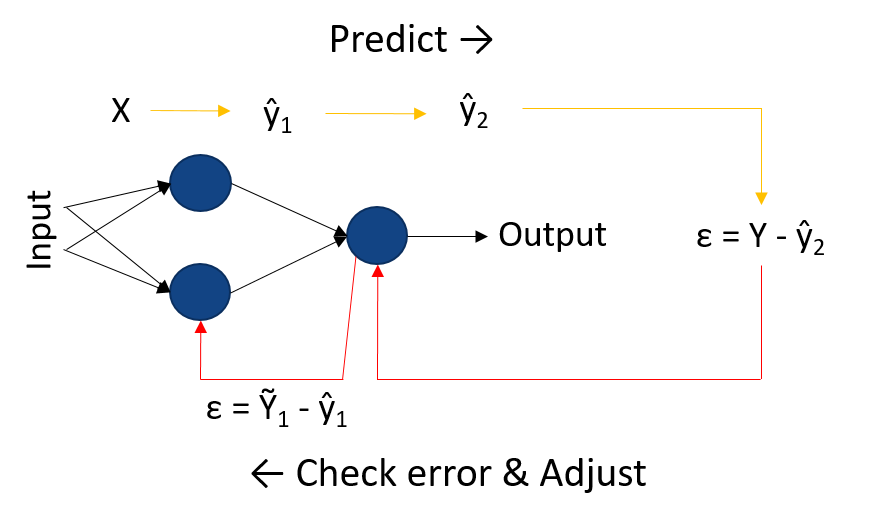
Chapter 2
Data Science, Machine Learning and Neural Networks.
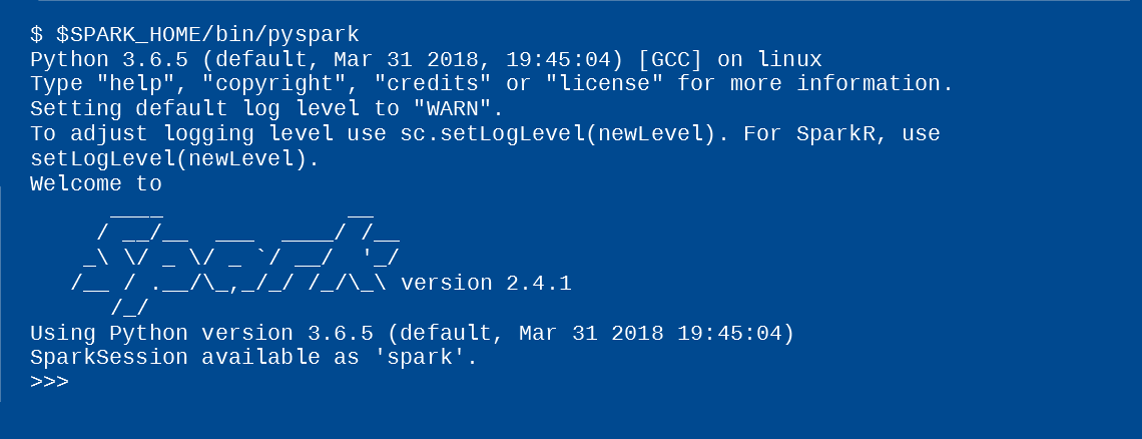
Chapter 3
Apache Spark, SparkML and Intel BigDL examples.
Scripts and Guide to Deploy the Environment
Because appropriately setting up a running Spark and BigDL environment is no small task we provide a pre-made, container-based solution for you to run the exercises and toy around. In that section you will find the necessary scripts and guidelines to manage and get your BigDL and Spark simulated environments up and running, as well as instructions on how to be able to run Jupyter notebooks, either the ones we provide as exercises or your own.
Copyright © Barcelona Supercomputing Center, 2019-2020 - All Rights Reserved - AI in DataCenters